Back
AIGC 2023.06.22Text-to-Speech Tools
2023.06.22Text-to-Speech (TTS) has been a well-established technology for years. As contemporary society becomes increasingly busy, people are recognizing the potential value of voice, and auditory perception is gradually becoming part of the new "sound economy." From the rise in podcast and audiobook audiences during the pandemic to the normalization of voice synthesis for movie narrations and voiceovers in short videos, our expectations for voice generation extend beyond the announcements in public transportation. We now desire comfortable human-machine interfaces that greet us naturally, like emotionally rich individuals, or smoothly read articles aloud. Such demands are believed to be gradually met through technological advancements. Here are some notable TTS tools:
1.Microsoft TTS

Microsoft TTS User Interface (Image Source: Microsoft TTS Website)
Microsoft TTS Website
Pricing: Free to use for the first twelve months.
Microsoft TTS is a voice generator developed by Microsoft. With its extensive voice library and advanced deep learning techniques, it has the capability to generate high-quality, natural-sounding speech directly online. Leveraging Microsoft's vast database, in addition to certain obscure languages surprisingly being capable of TTS conversion, popular languages such as English, German, and French offer a variety of voice options to choose from.
It is worth mentioning that Microsoft TTS provides excellent support for Chinese language with a diverse voice library. It distinguishes between different accents from various regions of China, including Traditional Chinese. Users can also choose between female and male voices, adjust the tone and speed according to their preference. The interface is user-friendly, allowing users to simply paste the text and instantly convert and download the speech on the website. As a commercial product, Microsoft TTS is a feature embedded within the Microsoft Azure platform, and users with a Microsoft account can enjoy a free trial period of 12 months.
2.Bark TTS

User Interface of Bark TTS hugging face(Image Source)
Bark TTS Website
Pricing:Free open source
Bark TTS is an AI model developed by the Suno team. In addition to the basic functionality of text-to-speech conversion, its most significant feature is the ability to simulate non-verbal communication. Non-verbal communication refers to the use of facial expressions, body language, intonation, and other factors to complement linguistic meaning when conveying messages. Bark TTS can simulate varying tones and emotions, and even produce sounds like laughter or throat-clearing through text commands, creating a lively and distinctive experience compared to other speech synthesis tools. Currently, access to Bark TTS's playground requires application, or users can download it from GitHub for local operation or use it on the Hugging Face platform.
Bark TTS showcases the future of fully generated text-to-audio models through different approaches from traditional TTS techniques. It does not prioritize high-definition, studio-level quality of the speech. Instead, it resembles a speech version of ChatGPT with higher variation in outputs. It can even use an A-language model to generate a unique accent while speaking in B language. Although it is currently unstable, it represents an important direction in the field of speech synthesis.
3.D-ID
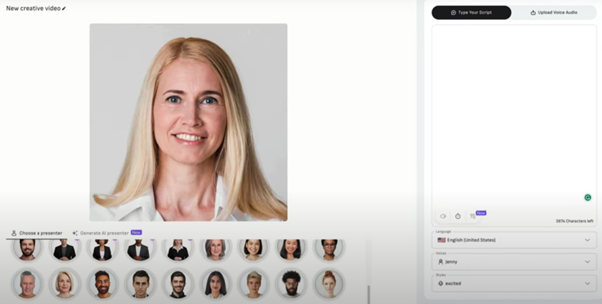
User Interface of D-ID(Image Source)
D-ID Website
Pricing:Free trial for 14 days(for 5 min film), with pricing ranging from $5 to $300 per month, depending on usage.
D-ID's original proprietary product was designed to remove crucial biometric data from images and videos, preventing machines from identifying individuals' biometric information. This ensures that personal identity information contained within images and videos cannot be exploited by law-breakers, making it a novel form of protection. However, their recently introduced technology called "Speaking Portraits" has become a popular application in the current AI-generated content trend. The reason is that it only requires a single static headshot photo, and through inputting text or recording an audio file, it can speak like a news anchor, even with head movement and blinking. When combined with other image generation tools, it creates a dynamic virtual avatar that can be used in various applications. For example, it can animate old photos of ancestors, act as a radio host, or even give a visual representation to chatbots.
D-ID currently offers a diverse range of integrated services, including stable diffusion for generating lifelike portraits and Microsoft TTS for speech synthesis. These services enable users to create avatars seamlessly on their website. Additionally, they have developed chat.D-ID, which integrates with ChatGPT to provide real-time facial lip movements and expressions during conversations, allowing users to better observe nuanced information. D-ID's current pricing model includes a free trial for 14 days with a five-minute video generation limit. Afterward, pricing ranges from $6 to $300, depending on the chosen services.
Brief Summary
These voice generation tools allow users to produce compelling and high-quality audio content, such as radio dramas, podcasts, or explanatory videos. The speed and adaptability of these technologies also enhance the educational experience and provide a more comfortable experience for individuals with sensory impairments. Moreover, in the current trend where attention is a valuable asset, businesses can create tailored brand voices to further enhance brand recognition and emotional connection with consumers. However, recent advancements like Google's AudioLM and SoundStorm deserve our attention as well. These technologies can capture vocal characteristics from as short as three seconds of speech and simulate the voice, potentially posing risks of voice forgery and sound deception. In the future, it will be crucial to strengthen corresponding technological and legal regulations to address these concerns.